LLM API bills, and why a token costs what it costs
How input and output tokens get priced, why output runs 5-6x more, and how prompt caching cuts the input bill by 10x. Plus the hidden costs that ambush people.
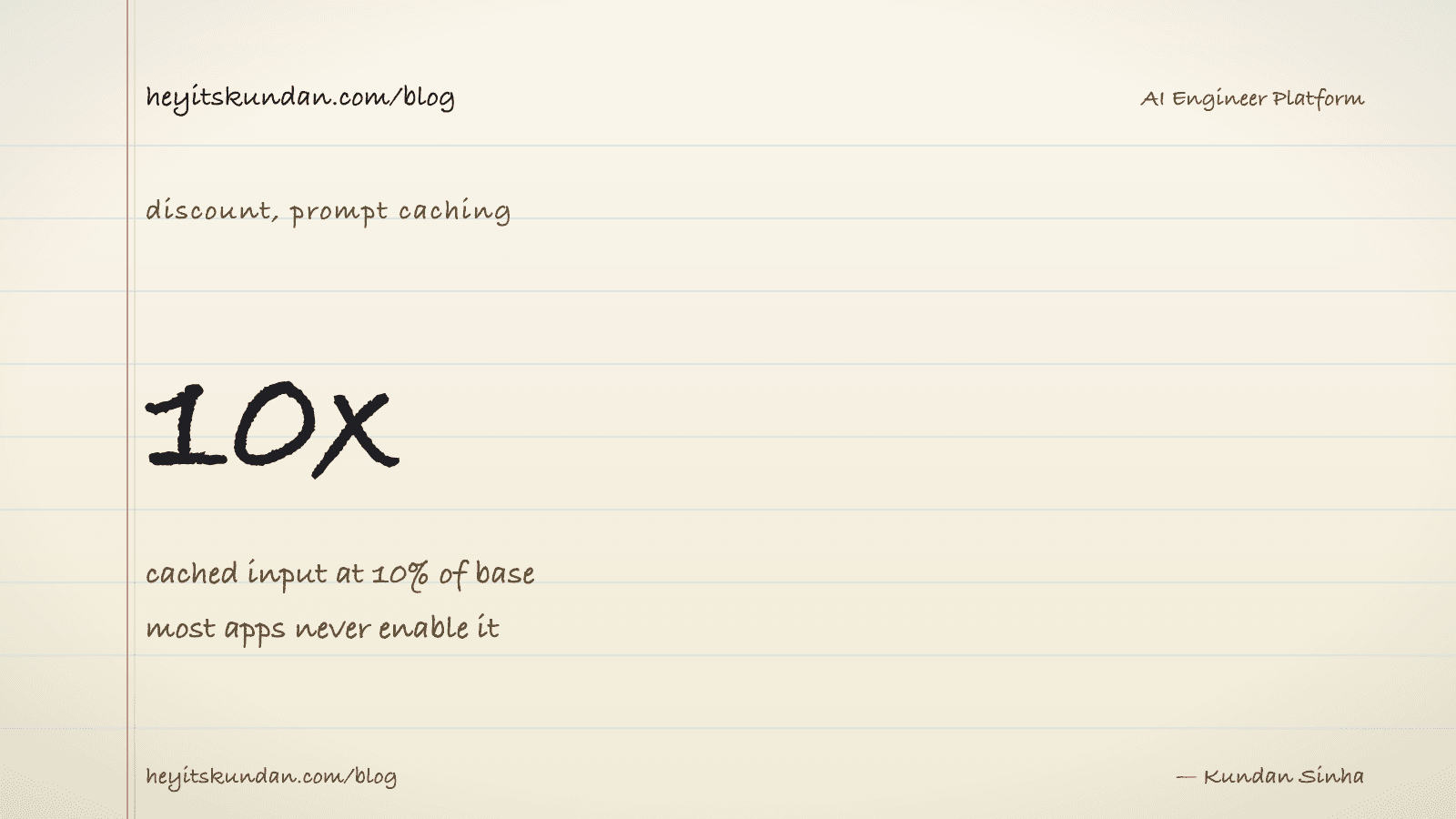
Someone I know shipped a tidy little summarizer feature and assumed it would cost about twenty bucks a month. The invoice came in at $4,000. Nothing was broken. The code did exactly what it was told. He just hadn't understood that an LLM API bill is one number multiplied across two prices: tokens in, tokens out. Get used to that and the bill stops surprising you.
This is post 6 of 7 in the AI Running series. The earlier posts were about the local-runtime side, the model on your own machine. This one is the cloud-API side: how token billing actually works, why output costs more than input, and how prompt caching changes the math by a factor of ten.
What a token actually is
A token is a chunk of text the model processes as one unit. Roughly:
- 1 token ≈ 4 characters of English.
- 1 token ≈ 0.75 of an English word.
- 1,000 tokens ≈ 750 words ≈ a page of text.
- 1M tokens ≈ a 750-page book.
The exact mapping is the model's tokenizer (BPE, SentencePiece, etc.). Different models slice the same text differently. Claude Opus 4.7 ships with a new tokenizer that produces up to 35% more tokens than 4.6 on the same input. So the same prompt costs 35% more even though the per-token price didn't budge. Always compare like-for-like on the same tokenizer.
For a rough feel:
- A short chat message is 10 to 50 tokens.
- A typical prompt with system instructions is 500 to 2,000 tokens.
- A document you're summarizing is usually 5,000 to 50,000 tokens.
- A full codebase loaded into context is 100,000 to 1,000,000 tokens.
Input vs output, and why output stings
Every API charges different prices for input and output. Output is always the pricier side. This catches everyone the first time.
A representative table for 2026, per million tokens:
| Model | Input | Output | Output multiple |
|---|---|---|---|
| Claude Opus 4.7 | $5 | $25 | 5x |
| Claude Sonnet 4.6 | $3 | $15 | 5x |
| Claude Haiku 4.5 | $0.80 | $4 | 5x |
| GPT-5.5 | $5 | $30 | 6x |
| Gemini 3.1 Pro | $4 | $20 | 5x |
| DeepSeek V4 | $0.30 | $1.20 | 4x |
The reason sits inside how inference works. Input tokens get processed in a single forward pass. The GPU chews through all of them at once, in parallel, in milliseconds. Output tokens come out one at a time, autoregressively. Each new output token needs a fresh forward pass over the entire context so far. A 1,000-token output runs the model 1,000 times.
That 5x or 6x ratio isn't a vendor being greedy. It's that asymmetry showing up in the price.
What this does to your bills
Two patterns trip people up.
Long context, short answers. You stuff 50,000 tokens of documentation into the prompt and ask for a one-line answer. Looks expensive because of all that input, but it's actually cheap. 50,000 input tokens at $5/M is $0.25. The 50-token answer is rounding error.
Short prompts, long answers. You hand a model a 200-token brief and ask for a 5,000-token report. Now the math flips. 200 input plus 5,000 output at $5/$25 per M is $0.001 + $0.125 = $0.126. The output runs the show. Do that 1,000 times and you're at $126.
Code generation, document drafting, agentic loops: all output-heavy. Q&A over a knowledge base is input-heavy. Always know which mode your workload sits in.
Prompt caching, the discount nobody turns on

The biggest cost lever in 2026 isn't picking a cheaper model. It's caching the parts of your prompt that never change.
Most production prompts open with a long stable header: the system prompt, tool definitions, retrieved documents, few-shot examples. Then the user's actual message comes at the end. That header might be 5,000 tokens that stay identical call after call. Without caching, you pay full input price for those 5,000 tokens every single time. With caching, you pay full price once, then 10% of input price on every later call inside the cache window (5 minutes by default on Anthropic, longer on others).
Run the numbers on Claude Opus 4.7:
- Without cache: a 5,000-token header at $5/M is $0.025 per call. Across 10,000 calls, $250.
- With cache: $0.025 the first time, then 5,000 tokens × $0.50/M = $0.0025 per call. Across 10,000 calls, $25 + $0.025 = $25.
A 10x cut on the input portion of your bill. Most production AI apps could shave 50 to 80% off their total spend just by caching the system prompt. Most don't. They wrote the integration before caching existed and never circled back.
If you're building anything that hits an LLM API more than 100 times a day with a stable header, caching is the first thing to reach for. Not a cleverer prompt. Not a smaller model. Caching.
A worked example
Say you've got a code-review bot. For every PR it gets:
- A 4,000-token system prompt (rules, style guide, examples). Stable.
- A 2,000-token diff. Changes per call.
- It outputs a 1,500-token review.
100 reviews a day, 30 days a month, on Sonnet 4.6 ($3 input, $15 output, $0.30 cached input).
Without caching:
- Input: (4,000 + 2,000) × 100 × 30 × $3/M = $54.
- Output: 1,500 × 100 × 30 × $15/M = $67.50.
- Total: $121.50/month.
With caching:
- Cached input: 4,000 × 100 × 30 × $0.30/M = $3.60.
- Fresh input: 2,000 × 100 × 30 × $3/M = $18.
- Output: $67.50 (unchanged).
- Total: $89.10/month.
A 27% cut from one config change. And the percentage climbs as the cached chunk grows.
The costs hiding off the price sheet
Three things that don't show up in the headline number.
Tokenizer drift. Like I said up top, Opus 4.7's tokenizer produces about 35% more tokens than 4.6 on the same English input. And the claim that "Hindi and Devanagari cost more" is real: non-Latin scripts often tokenize 2 to 3x worse than English on the same model.
Reasoning tokens. Reasoning-mode models (GPT-5.5 high, Claude with extended thinking) generate hidden chain-of-thought tokens before the final answer. Those get billed as output. A "high-reasoning" answer can cost 10x what a normal one does.
Tool calls. When the model calls a tool, the tool's response goes back into context as input on the next call. An agent grinding through 20 tool calls in a loop can rack up 50,000+ input tokens for what looked like one little user request.
So log your real token counts in production. The bill is downstream of those numbers, and the numbers are almost always higher than your back-of-envelope guess.
Picking a model on cost
A working heuristic for 2026:
- High-volume, low-stakes work (classification, summarization, simple chat): Haiku 4.5, GPT-5-mini, or DeepSeek V4. Below $1/M output. Bills stay small.
- Daily driver, real work (coding, drafting, agentic loops): Sonnet 4.6 or GPT-5.4. Around $15/M output. Best price-per-intelligence ratio.
- Frontier reasoning, hard problems: Opus 4.7 or GPT-5.5 high. $25 to $30/M output. Pay it when it matters. Don't pay it for everything.
One trap is using Opus for tasks Haiku could handle. The other is using Haiku for tasks that need Opus, then burning a week debugging the model's mistakes. Neither one saves you money.
What's next
So far this has all been about the bill. But dollars aren't the only thing leaving your machine when you call an API. Your data goes too. The next post is about what providers actually see, log, and do with the tokens you send them. That $4,000 invoice was the easy problem to spot.
From the dictionary
Terms used in this post
Quick reference for the 15 terms you met above. Each one comes from the AI dictionary.
- Artificial IntelligenceAI
- Umbrella term for software that performs tasks usually associated with human reasoning — language, perception, decision-making. Coined at the 1956 Dartmouth Summer Research Project. In everyday 2026 use, "AI" almost always means a large language model like ChatGPT, Claude, or Gemini, even though the textbook definition is much broader.
- e.g. When a product page says "AI-powered", it could mean a 70-billion-parameter LLM or a hand-written if-statement. The label moves with the times.
- APIGeneral
- Application Programming Interface. In LLM context: the HTTP endpoint a hosted model exposes (api.openai.com, api.anthropic.com). You send JSON, you get tokens back. The cloud-inference contract.
- ClaudeAI
- Anthropic's family of LLMs (Opus, Sonnet, Haiku) and consumer chat product at claude.ai. Used in this blog's tooling for drafting and dictionary work; also powers Claude Code, the CLI agent.
- e.g. This blog's create-post skill drafts inline using Claude.
- Context WindowNLP
- The maximum number of tokens an LLM can take in for a single forward pass. Everything the model knows about your current conversation has to fit inside this window — anything outside is invisible.
- Few-ShotNLP
- Showing the LLM a handful of input/output examples in the prompt before the real query, so it picks up the pattern. Cheap and effective; usually the next thing to try after a plain prompt.
- GeminiAI
- Google's family of LLMs and the consumer chat product at gemini.google.com. Tightly integrated with Google's search index and Workspace apps.
- e.g. Gemini is Google's answer to ChatGPT, with native access to Search.
- GPTAI
- OpenAIs family of large language models — Generative Pre-trained Transformer. GPT-4 (2023) and successors are the most widely used closed-source LLMs in production.
- GPUGeneral
- A chip built for massive parallel arithmetic. The reason deep learning took off in the 2010s — GPUs make matrix multiplication fast enough to train deep networks in days instead of years. Nvidia dominates the market.
- InferenceML
- Running a trained model on a new input to produce an output. A single forward pass through the network with frozen weights. Much cheaper than training, which is why every LLM API exists.
- Large Language ModelAI
- A deep-learning model trained on huge volumes of text to predict the next token given the previous ones. Scaling next-token prediction to billions of parameters yields the chat-like behaviour of ChatGPT, Claude, and Gemini. Capabilities are bounded by training data and the context window.
- e.g. Claude is an LLM — it reads your message as tokens and generates a response one token at a time.
- ModelML
- In ML, a model is a file of learned numbers (parameters or weights) plus an architecture that tells the program how to use them. Loading a model means reading those numbers; running it means doing arithmetic with them.
- PromptNLP
- The text you send to an LLM. Includes any system prompt, conversation history, retrieved context, and your actual question. The prompt is the only thing you can change without retraining.
- Prompt CachingAI
- Caching the model state for a stable prefix of a prompt so repeat calls skip recomputing it. Anthropic and OpenAI both expose this via API; cached tokens cost 5-10x less and have a 5-minute TTL on Anthropic. Critical for cost when you reuse system prompts or RAG context across requests.
- System PromptNLP
- A special instruction at the start of an LLM conversation that sets role, behaviour, format, and constraints. Most "the model isnt doing what I want" problems are solved here, before reaching for RAG or fine-tuning.
- TokenNLP
- The unit an LLM operates on — roughly a word or piece of one. English averages around 4 characters per token. Tokens are the unit of computation, the unit of API billing, and the unit the context window is measured in.
Rate this article
How helpful did you find this?
- 01
Where AI actually runs: cloud, local, edge
March 16, 2026
- 02
The major LLMs in 2026
March 18, 2026
- 03
What it takes to run a model on your own machine
March 21, 2026
- 04
Why Apple Silicon punches above its weight on local LLMs
March 23, 2026
- 05
The runtimes: llama.cpp, Ollama, LM Studio
March 26, 2026
- 06
LLM API bills, and why a token costs what it costs
March 28, 2026
- 07
What leaves your machine when you use AI
March 31, 2026
Newsletter
Get new articles in your inbox
AI engineering, LLM systems, and software architecture — no filler.
No spam. Unsubscribe any time.
Discussion
Comments
Leave a note about the article, architecture choices, or what you would build next.
Loading comments...