Prompt, RAG, fine-tune: three ways to shape a model
Three levers for shaping what an LLM does: prompting (ask better), RAG (give it the right context), fine-tuning (change the weights). What each costs, what each fixes, and how to pick.

This is post 8 of 8 in the Foundations series. The first seven posts were all building toward one practical question: you've got an LLM and a use case, so how do you actually make it work for you?
There are three levers. They aren't substitutes. Each one fixes a different problem, at a different cost.
The three levers
Prompting. Change what you write in the message: system prompts, instructions, examples in-context, hints about the output format. No code, no infrastructure. You iterate in seconds.
RAG. Pull relevant data from your own corpus and paste it into the context window before the question. This needs a bit of infrastructure (a vector store, an embedding model, some retrieval code) but no model training. You iterate in minutes to hours.
Fine-tuning. Keep training the model on your own examples so new behaviour gets baked into the weights. This needs real infrastructure (a training pipeline, a GPU budget, an eval harness) and a fresh re-training run every time you want a change. You iterate in hours to days, sometimes longer.
All three change what comes out of the model. None of them change what the model is. The one exception is fine-tuning, and even then it only changes a copy.
What each one actually changes
Prompting changes the input. The weights stay frozen and the context window holds whatever you wrote. Good prompting is mostly about handing the model the right framing, the right format, and a concrete example or two ("few-shot"). The most under-rated trick is simply telling the model what role to play and what shape the output should take. Most "the model isn't doing what I want" problems die right here.
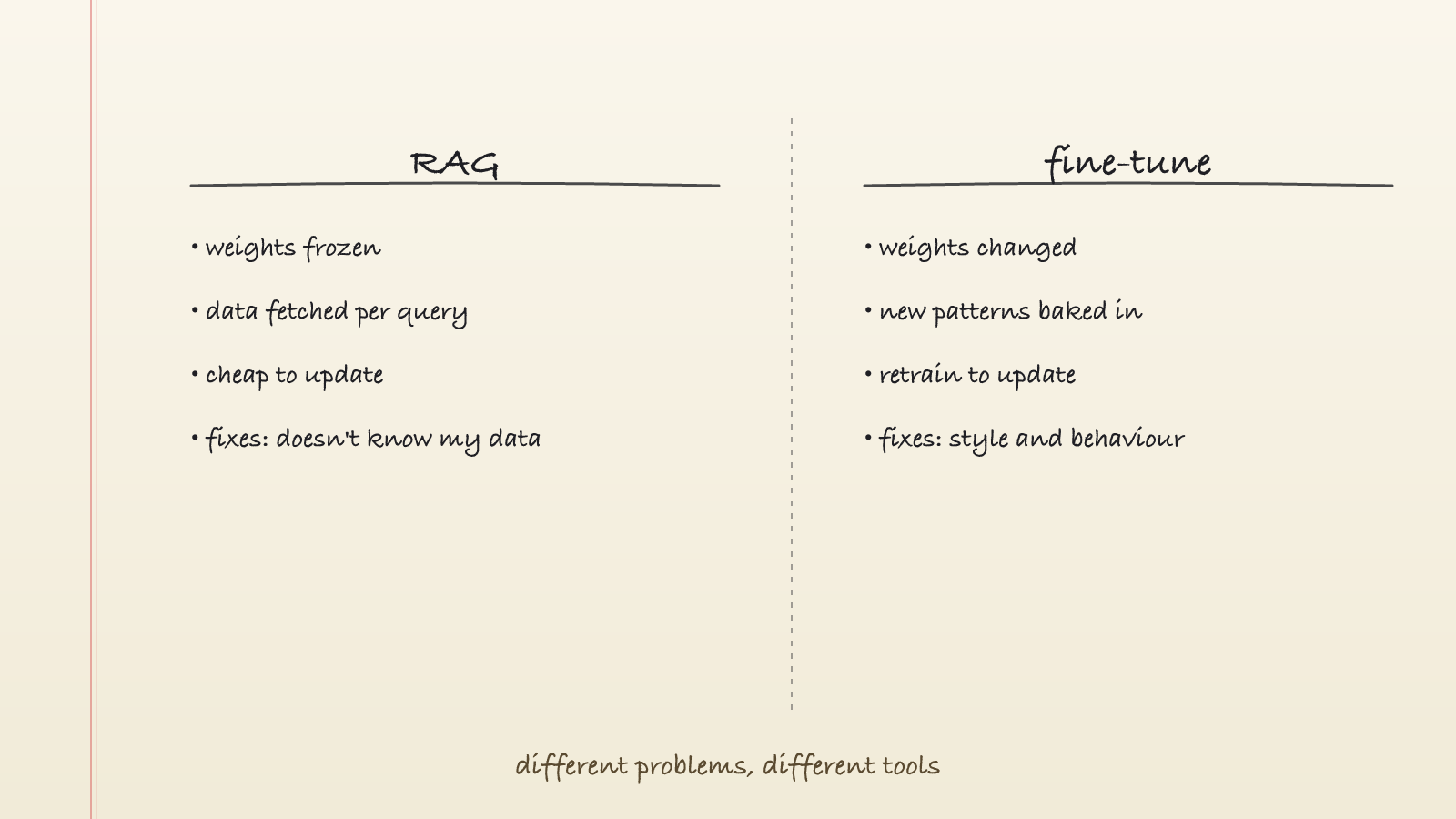
RAG also changes the input. It just builds that input fresh for every query out of whatever it retrieved. The weights are still frozen, and the model sees a different prompt each time depending on what was relevant. RAG fixes "the model doesn't know my data." It does nothing for "the model talks in the wrong tone." That one is still a prompting job.
Fine-tuning changes the weights. The numbers in the model file are literally different afterwards. Patterns that were rare in the original training become the default in the fine-tuned version. Done well, it bakes in behaviours and styles. Done badly, it makes the model worse at general tasks (catastrophic forgetting) without making it meaningfully better at the one you cared about.
What each one costs
Figures that hold roughly true in 2026.
- Prompting is free in dollars. It costs your time, and most of that time is iteration cycles, which is why a fast prompt-and-test loop beats clever prompts.
- RAG runs tens to hundreds of dollars to stand up a small system, a low monthly bill for vector storage, plus your inference cost. Embedding 10 million tokens is about a dollar at current OpenAI rates.
- Fine-tuning at its cheapest is a hosted fine-tune of a small model for a few hundred dollars. At its largest, a custom fine-tune of a 70B-plus model, it runs into tens of thousands. Add the eval cost on top, because without good evals a fine-tune is a coin flip.
All three pile inference cost on top, since you're still calling the model once per request. RAG adds the most, because it grows the prompt.
When to reach for which
These are my rules of thumb, after building real things with all three.
Start with prompting. Always. Most problems are prompting problems in disguise. If the system prompt can fix it, fix it there and stop.
Reach for RAG when the model needs facts it doesn't have. Your docs, your codebase, a customer's account history, anything private or anything that changes. When prompting alone isn't enough, RAG is the right answer roughly 80% of the time.
Reach for fine-tuning only once you've maxed out prompting and RAG and the gap that's left is style or behaviour. Fixed output formats, a domain-specific tone, classification at a scale where the prompt would otherwise be enormous. Fine-tuning is rarely the first answer. It's usually the last 10%.
I see the same two mistakes over and over. The first: teams jump straight to fine-tuning because it sounds impressively technical, then realise they were fixing a prompting problem all along. The fine-tune works, sure, but a prompt would have worked for a fraction of the cost. The second: cramming everything into the prompt as the system grows, until the prompt is its own corpus and the right move is to retrieve from it instead of shipping the whole thing every time.
Combine them
Real systems run all three at once. A production setup tends to look like this.
- A carefully written system prompt carrying the role, the format, and the constraints.
- RAG fetching the relevant slice of your corpus for each query.
- Optionally, a fine-tuned model that's already fluent in your specific output format.
The levers multiply, they don't add. A great prompt with the wrong context still fails. Great context with a sloppy prompt still fails. A great fine-tune with neither barely matters.
And that closes the Foundations series. Eight posts, one arc: from "AI is mostly a marketing word" to "here's the exact lever to reach for, and why."
You now know what these models are and how to bend them to your needs. The obvious next question is where they actually run. The cloud? The laptop on your desk? The phone in your pocket? Each choice carries its own tradeoffs in hardware, cost, privacy, and speed, and that's the whole subject of the next series, AI Running.
From the dictionary
Terms used in this post
Quick reference for the 16 terms you met above. Each one comes from the AI dictionary.
- Artificial IntelligenceAI
- Umbrella term for software that performs tasks usually associated with human reasoning — language, perception, decision-making. Coined at the 1956 Dartmouth Summer Research Project. In everyday 2026 use, "AI" almost always means a large language model like ChatGPT, Claude, or Gemini, even though the textbook definition is much broader.
- e.g. When a product page says "AI-powered", it could mean a 70-billion-parameter LLM or a hand-written if-statement. The label moves with the times.
- Context WindowNLP
- The maximum number of tokens an LLM can take in for a single forward pass. Everything the model knows about your current conversation has to fit inside this window — anything outside is invisible.
- EmbeddingNLP
- A list of numbers (a vector) that represents the meaning of a piece of text. Two pieces of text with similar meanings have embeddings close together in space. The basis of vector search and most modern retrieval.
- Few-ShotNLP
- Showing the LLM a handful of input/output examples in the prompt before the real query, so it picks up the pattern. Cheap and effective; usually the next thing to try after a plain prompt.
- Fine-TuningML
- Continuing to train an existing model on new data, so the new patterns get baked into the weights. Distinct from RAG (which only changes the prompt) and prompting (which changes nothing).
- GPUGeneral
- A chip built for massive parallel arithmetic. The reason deep learning took off in the 2010s — GPUs make matrix multiplication fast enough to train deep networks in days instead of years. Nvidia dominates the market.
- InferenceML
- Running a trained model on a new input to produce an output. A single forward pass through the network with frozen weights. Much cheaper than training, which is why every LLM API exists.
- Large Language ModelAI
- A deep-learning model trained on huge volumes of text to predict the next token given the previous ones. Scaling next-token prediction to billions of parameters yields the chat-like behaviour of ChatGPT, Claude, and Gemini. Capabilities are bounded by training data and the context window.
- e.g. Claude is an LLM — it reads your message as tokens and generates a response one token at a time.
- ModelML
- In ML, a model is a file of learned numbers (parameters or weights) plus an architecture that tells the program how to use them. Loading a model means reading those numbers; running it means doing arithmetic with them.
- PromptNLP
- The text you send to an LLM. Includes any system prompt, conversation history, retrieved context, and your actual question. The prompt is the only thing you can change without retraining.
- RAGNLP
- Retrieval-Augmented Generation: search your corpus for relevant text, paste it into the LLMs context window, then ask the question. The models weights are unchanged; only the prompt is augmented.
- System PromptNLP
- A special instruction at the start of an LLM conversation that sets role, behaviour, format, and constraints. Most "the model isnt doing what I want" problems are solved here, before reaching for RAG or fine-tuning.
- TokenNLP
- The unit an LLM operates on — roughly a word or piece of one. English averages around 4 characters per token. Tokens are the unit of computation, the unit of API billing, and the unit the context window is measured in.
- TrainingML
- The expensive one-time process of running a learning algorithm over data until the models parameters settle into useful values. Frontier-model training costs $100M+ and tens of thousands of GPUs.
- Vector DatabaseData
- A database optimised for storing and searching embeddings — finding the K nearest vectors to a query vector. Examples: Pinecone, Weaviate, pgvector. The retrieval engine in most RAG systems.
- WeightsML
- The numbers inside a trained model. They start out random and get adjusted during training until they encode the patterns in the data. "Open weights" means the trained numbers are downloadable; it does not mean the training data or code is open.
Rate this article
How helpful did you find this?
- 01
AI, in plain words
February 24, 2026
- 02
Inside AI: machine learning and deep learning
February 26, 2026
- 03
What makes a model: data and algorithm
March 1, 2026
- 04
How a model learns: training and inference
March 3, 2026
- 05
From models to LLMs
March 6, 2026
- 06
The context window, and why models hallucinate
March 8, 2026
- 07
RAG: giving a model memory it doesn't have
March 11, 2026
- 08
Prompt, RAG, fine-tune: three ways to shape a model
March 13, 2026
Newsletter
Get new articles in your inbox
AI engineering, LLM systems, and software architecture — no filler.
No spam. Unsubscribe any time.
Discussion
Comments
Leave a note about the article, architecture choices, or what you would build next.
Loading comments...