The context window, and why models hallucinate
An LLM only sees a fixed-size slice of text at a time. When it doesn't know something, it predicts anyway. That's a hallucination, not a bug.

Post 5 closed on a constraint: an LLM can only see so much text at once. That constraint has a name, the context window, and it's the single most important number to understand about any LLM you touch.
This is post 6 of 8 in the Foundations series.
What the context window is
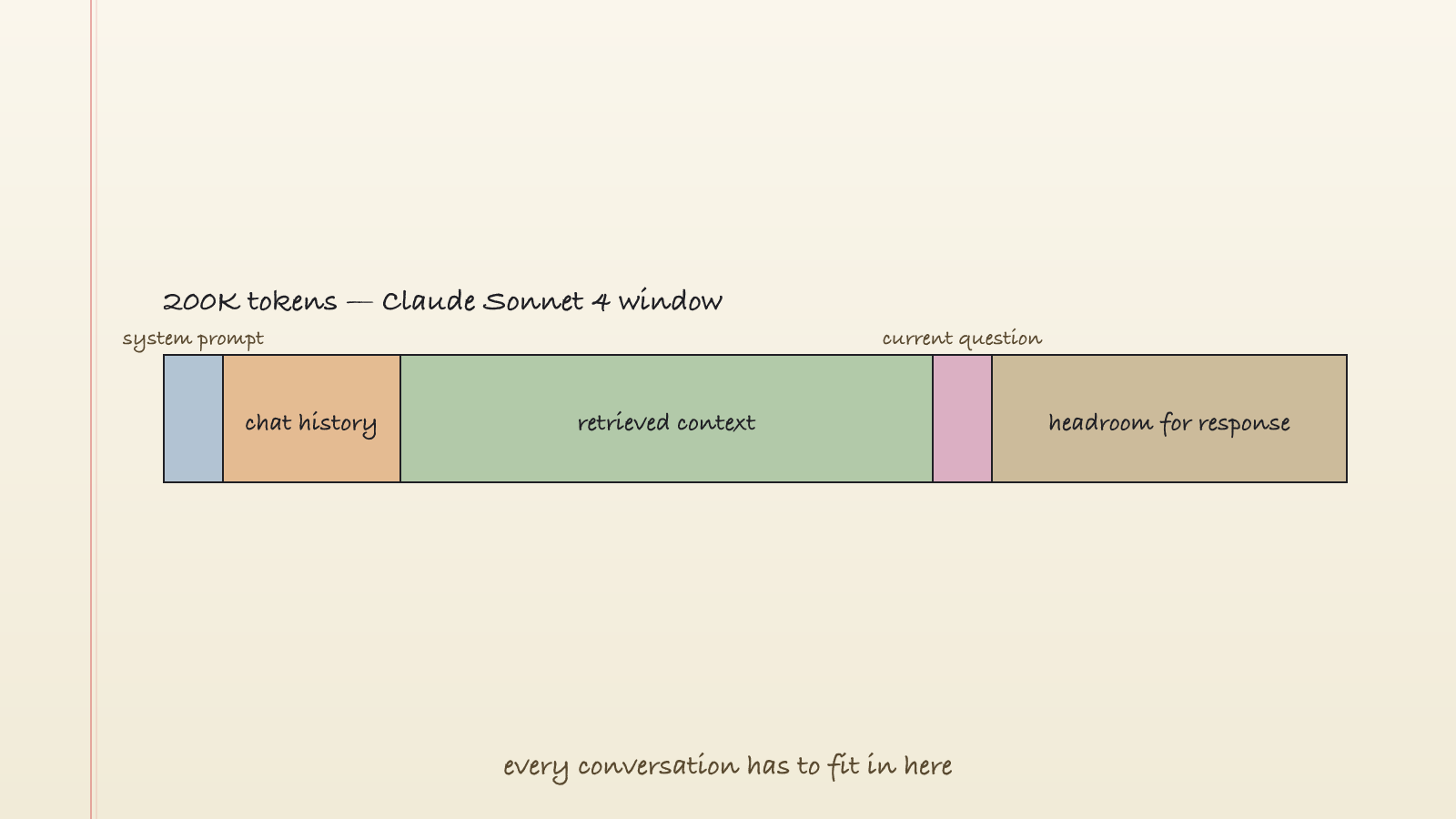
The context window is the maximum number of tokens an LLM can take in for a single forward pass. Everything the model knows about your current conversation has to fit inside it: the system prompt, the chat history, the document you pasted, your last question. Anything that doesn't fit is simply invisible. As far as the model is concerned, it doesn't exist.
The cleanest way I've found to picture it is working memory. Long-term memory lives in the trained weights, everything the model absorbed during training. Short-term memory is the context window, everything it can see this very second.
Some numbers, as of early 2026.
- GPT-4 Turbo: 128K tokens, about 300 pages of text.
- Claude Sonnet 4: 200K tokens. Claude Opus 4 with the 1M flag: a full million.
- Gemini 2.5 Pro: 1M and up.
- Llama 3 base: 8K, though most fine-tunes stretch it to 128K.
Since a token is roughly 4 characters of English, 200K tokens is around 150,000 words, about the length of a long novel. A million tokens is several of them.
What "long context" actually costs
Big windows aren't free. In the plain version of the transformer, the attention mechanism scales with the square of the sequence length. So doubling the context doesn't double the cost. It roughly quadruples it.
Providers have engineered around the worst of that with sparse attention and caching, but the bill still climbs three ways.
- Sending 200K input tokens to a frontier model costs proportionally more than sending 2K, every single time.
- Generation slows as the context grows. The first token after a 500K-token prompt lands in seconds, not milliseconds.
- Quality sags in the middle. Models reliably pull facts out of the first and last 10% of a long context. The middle 80%, the well-documented "lost in the middle" effect, is where they quietly drop things.
So more context isn't automatically better. The right context, ordered well, beats a firehose of everything you happen to have.
Why models hallucinate
Here's where the next-token picture from post 5 earns its keep. Mechanically, an LLM is a function that produces a probability distribution over the next token. It always produces one. It can't say "I don't know" unless it was specifically trained to recognise the moments when "I don't know" is itself the most likely next token.
So when you ask about something that genuinely isn't in its training data and isn't in its current context, the math doesn't politely stop. It reaches for the next most plausible-looking continuation. That continuation is a hallucination: output shaped exactly like an answer, grounded in nothing real.
This is the part worth internalising. Hallucinations aren't bugs. They're the model doing precisely what it was trained to do, aimed at a question whose answer was never available to it. Which means the fix isn't only "train the model to admit ignorance." It's getting the right information into the context window so there's something true for it to predict from.
And that points straight at the practical move. If the model has to answer questions about your company docs, your codebase, or last week's news, you have to get those tokens into the window somehow. Which is exactly what retrieval is for.
Things this suddenly explains
Once the window clicks, a pile of everyday weirdness makes sense.
- Why ChatGPT can't tell you today's date unless the system prompt slipped it in. It isn't in the context otherwise.
- Why a model confidently invents a citation that doesn't exist. "Smith et al., 2021" is a high-probability shape in academic-sounding text, whether or not that paper was ever real.
- Why pasting a long PDF and then asking beats asking from memory. You moved the answer from "hopefully it remembers" to "definitely in the context."
- Why your AI coding assistant sometimes calls a function that isn't in your codebase. It's hallucinating a plausible-sounding API.
If the answer to most LLM problems is "put the right tokens in the window," the obvious next question is how you choose which ones. That's RAG, and it's post 7.
From the dictionary
Terms used in this post
Quick reference for the 19 terms you met above. Each one comes from the AI dictionary.
- Artificial IntelligenceAI
- Umbrella term for software that performs tasks usually associated with human reasoning — language, perception, decision-making. Coined at the 1956 Dartmouth Summer Research Project. In everyday 2026 use, "AI" almost always means a large language model like ChatGPT, Claude, or Gemini, even though the textbook definition is much broader.
- e.g. When a product page says "AI-powered", it could mean a 70-billion-parameter LLM or a hand-written if-statement. The label moves with the times.
- AttentionDL
- The mechanism inside a transformer that lets the model look at every previous token in the sequence and weigh its relevance. Attention scales quadratically with sequence length, which is why long context is expensive.
- ChatGPTAI
- OpenAIs consumer chat product, launched November 30, 2022. The first LLM to reach mass adoption — 100 million users in two months. The product most people mean when they say AI today.
- ClaudeAI
- Anthropic's family of LLMs (Opus, Sonnet, Haiku) and consumer chat product at claude.ai. Used in this blog's tooling for drafting and dictionary work; also powers Claude Code, the CLI agent.
- e.g. This blog's create-post skill drafts inline using Claude.
- Context WindowNLP
- The maximum number of tokens an LLM can take in for a single forward pass. Everything the model knows about your current conversation has to fit inside this window — anything outside is invisible.
- DatasetData
- The collection of examples a model learns from during training. The shape, size, quality, and bias of the dataset determines almost everything about the resulting model.
- GeminiAI
- Google's family of LLMs and the consumer chat product at gemini.google.com. Tightly integrated with Google's search index and Workspace apps.
- e.g. Gemini is Google's answer to ChatGPT, with native access to Search.
- GPTAI
- OpenAIs family of large language models — Generative Pre-trained Transformer. GPT-4 (2023) and successors are the most widely used closed-source LLMs in production.
- HallucinationNLP
- When an LLM produces output that looks like an answer but isnt grounded in anything real. Not a bug — the consequence of next-token prediction applied to questions where the right answer wasnt available.
- Large Language ModelAI
- A deep-learning model trained on huge volumes of text to predict the next token given the previous ones. Scaling next-token prediction to billions of parameters yields the chat-like behaviour of ChatGPT, Claude, and Gemini. Capabilities are bounded by training data and the context window.
- e.g. Claude is an LLM — it reads your message as tokens and generates a response one token at a time.
- ModelML
- In ML, a model is a file of learned numbers (parameters or weights) plus an architecture that tells the program how to use them. Loading a model means reading those numbers; running it means doing arithmetic with them.
- PromptNLP
- The text you send to an LLM. Includes any system prompt, conversation history, retrieved context, and your actual question. The prompt is the only thing you can change without retraining.
- RAGNLP
- Retrieval-Augmented Generation: search your corpus for relevant text, paste it into the LLMs context window, then ask the question. The models weights are unchanged; only the prompt is augmented.
- System PromptNLP
- A special instruction at the start of an LLM conversation that sets role, behaviour, format, and constraints. Most "the model isnt doing what I want" problems are solved here, before reaching for RAG or fine-tuning.
- TokenNLP
- The unit an LLM operates on — roughly a word or piece of one. English averages around 4 characters per token. Tokens are the unit of computation, the unit of API billing, and the unit the context window is measured in.
- TrainingML
- The expensive one-time process of running a learning algorithm over data until the models parameters settle into useful values. Frontier-model training costs $100M+ and tens of thousands of GPUs.
- TransformerDL
- The neural-network architecture every modern LLM is built on. Introduced by Google in the 2017 paper "Attention Is All You Need". GPT, Claude, Gemini, Llama, Mistral — all transformers.
- WeightsML
- The numbers inside a trained model. They start out random and get adjusted during training until they encode the patterns in the data. "Open weights" means the trained numbers are downloadable; it does not mean the training data or code is open.
- APIGeneral
- Application Programming Interface. In LLM context: the HTTP endpoint a hosted model exposes (api.openai.com, api.anthropic.com). You send JSON, you get tokens back. The cloud-inference contract.
Rate this article
How helpful did you find this?
- 01
AI, in plain words
February 24, 2026
- 02
Inside AI: machine learning and deep learning
February 26, 2026
- 03
What makes a model: data and algorithm
March 1, 2026
- 04
How a model learns: training and inference
March 3, 2026
- 05
From models to LLMs
March 6, 2026
- 06
The context window, and why models hallucinate
March 8, 2026
- 07
RAG: giving a model memory it doesn't have
March 11, 2026
- 08
Prompt, RAG, fine-tune: three ways to shape a model
March 13, 2026
Newsletter
Get new articles in your inbox
AI engineering, LLM systems, and software architecture — no filler.
No spam. Unsubscribe any time.
Discussion
Comments
Leave a note about the article, architecture choices, or what you would build next.
Loading comments...